- Anthropotechnics
- Dossier Overview
- Anthropotechnics for the AnthropoceneJohn Tresch
- Contra Diction.
Speech Against ItselfLawrence Abu Hamdan
- Dancing (the) TechnosphereTechnosphere Editorial
- Larp as TechnologyLizzie Stark
- On Anthropotechnics and Physical PracticeNik Kosmas
- Potency and Partial Knowledge.
An ExerciseJeremy BolenAndrew Yang
- Worshipping Along the Routes of Migration: Religion as InfrastructureGerda Heck
- Arctic
- Dossier Overview
- Living Arctic InfrastructuresRafico Ruiz
- On Land and Lakes: Colonizing the NorthJohn LawLiv Østmo
- Sever. Pre-emptive Strategy for an Open ArcticSever
- Sitting On Top of the World: Meridional Media, Arctic Condescension, and Northern TechniquesJamie Allen
- The Arctic Upside DownKaren Pinkus
- The Fight for Alaska's Arctic Has Just BegunSubhankar BanerjeeLois Epstein
- The Lena Is Worthy of Baikal: Defining Remoteness Across the North and the EastKsenia Tatarchenko
- Borders
- Dossier Overview
- Citizenship and Technologies of BorderingKim Rygiel
- Deportation and the Technification of Force: Violence in DemocracyChowra Makaremi
- GeotraumaMatija KraljAna Dana Beroš
- On the Operation of Border RegimesBernd KasparekIsabelle Saint-Saëns
- Worshipping Along the Routes of Migration: Religion as InfrastructureGerda Heck
- Creolized Technologies
- Dossier Overview
- A Caribbean Taste of Technology: Creolization and the Ways-of-Making of the Dancehall Sound SystemJulian Henriques
- Creole TechnologiesDavid Edgerton
- Creolized Technologies of DemoralizationElisa T. Bertuzzo
- Memories of the Yagán: The Chilean Automobile for the PeopleEden Medina
- Race and Technology: A Creole HistoryLouis Chude-Sokei
- The Shipworm and the
TelegraphOn Barak
- Earth
- Dossier Overview
- A Legacy of the TechnosphereJan ZalasiewiczAnne-Sophie Milon
- Möbius Trip. The Technosphere and Our Science Fiction RealityDorion Sagan
- Sensing Air and Generating Worlds of DataJennifer Gabrys
- Technosphere and TechnoecologyErich HörlPeter K. Haff
- The Biosphere in the Cosmic MediumVladimir Vernadsky
- The Virtual FieldEtienne Benson
- Ve Vm Vt. The Ideal Cosmic MessengersSasha EngelmannJol Thomson
- WhistlerNile Koetting
- continent. inter-view:
Bronislaw Szerszynski on the TechnosphereBronislaw Szerszynski
- Human
- Dossier Overview
- EmbeddedFrançois BucherLars Kulik
- GrindersHannes Wiedemann
- Instrumentality, or the Time of Inhuman ThinkingLuciana Parisi
- Is the Anthropocene …
A Doomsday Device?Cary WolfeClaire Colebrook
- Phenomenal MachinesNicole Koltick
- Race and Technology: A Creole HistoryLouis Chude-Sokei
- Solid/Solipsism RemedyJenna Sutela
- Somewhere, Somehow.
A Co-Evolution Story.Jonathan DongesSeth Denizen
- The Inclosure of ReasonAnil Bawa-Cavia
- Infrastructure
- Dossier Overview
- 1333AD, Port of Aden, YemenLaleh Khalili
- Ambient Infrastructures. Generator Life in NigeriaBrian Larkin
- Biometric CapitalismKeith Breckenridge
- Container Love, and FearAlexander Klose
- Infrastructure and AffectLisa Parks
- Larp as TechnologyLizzie Stark
- Sensing Air and Generating Worlds of DataJennifer Gabrys
- Technosphere VerticalityJohan Gärdebo
- Telecommunications.
A micro historyBirgit Schneider
- The Microwave Tower of the NYSE and the Physicality of FinanceDonald MacKenzie
- The Tower. A Concrete UtopiaFilip De BoeckSammy Baloji
- The Virtual FieldEtienne Benson
- UnderworldsUnderworlds
- Urban PornKeller Easterling
- Land & Sea
- Dossier Overview
- Changes in Fluvial Systems, River Sediments and DeltasJames P. M. Syvitski
- China’s “Blue Territory” and the Technosphere in Maritime East AsiaAndrew Chubb
- Jakarta: A Colonial Water-Management Fantasy ParkEtienne Turpin
- Kish, an Island Indecisive by DesignBabak AfrassiabiNasrin Tabatabai
- On Land and Lakes: Colonizing the NorthJohn LawLiv Østmo
- Port Cities: Nodes in the Global Petroleumscape between Sea and LandCarola Hein
- Rivers, Coasts, and the Geographical Dimensions of Patent InnovationRichard L. Hindle
- The Risk Equipment Deserves More Credit: Modeling, Epistemic Opacity, and ImmersionMatthijs Kouw
- Towards an Understanding of Anthropocene LandscapesAxel Braun
- When the Sea Begins to Dominate the LandDavor Vidas
- Machine Listening
- Dossier Overview
- 1. WaveNet: On Machine and Machinic ListeningStefan Maier
- 2. ULTRACHUNKJennifer WalsheMemo Akten
- 3. Couture Cosmetique: Transgendered electroacoustique symptomatic of the need for a cultural makeover (Or... What's behind all that foundation?)Terre Thaemlitz
- 4. Heteroglossic RiotBen Vida
- 5. Rainbow FamilyGeorge Lewis
- 6. 1935Florian Hecker
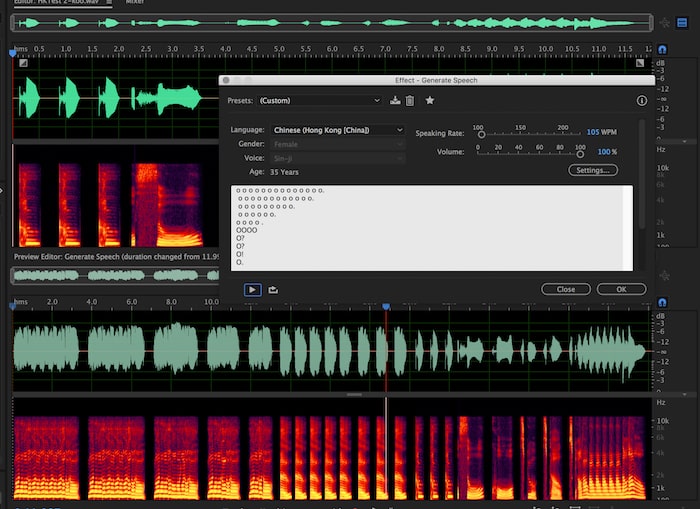
- 7. Mei-Jia & Ting-Ting & Chih-Fu & Sin-JiC Spencer Yeh
- 8. Supreme Connections Meets Video City in Maryanne Amacher’s Intelligent LifeAmy Cimini
- 9. Anti-WorldsYoneda Lemma
- Materials
- Dossier Overview
- A Recipe for Crafting Color: The Revival of Natural Dyeing in South IndiaAnnapurna Mamidipudi
- Explosives: Prime Movers of the AnthropoceneJens Soentgen
- Latent LifeSophia Roosth
- Phenomenal MachinesNicole Koltick
- The Material OrderSander van der LeeuwDaniel Niles
- To See a World in a Grain of Rice:
Temporalities of a Flowering Grass and the Great AccelerationElaine Gan
- Waste in Time and the Radioactivity of ObjectsEsther Leslie
- Metabolic Systems
- Dossier Overview
- Georama of TrashDesign Earth
- How the Technosphere Can Make the Earth More ActiveAxel Kleidon
- In the Sphere of Chemical TechnologyBenjamin Steininger
- Operational Landscapes and the Planetary Thünen TownNikos Katsikis
- Sitopia: The Power of Thinking Through FoodCarolyn Steel
- Soil’s metabolic rift: Metabolising hope, interrupting the mediumHuiying Ng
- Solid/Solipsism RemedyJenna Sutela
- Taking on the Technosphere: A Kitchen DebateGabrielle HechtPaul N. Edwards
- The Growth and Differentiation of Metabolism: Extended Evolutionary Dynamics in the TechnosphereManfred Laubichler
- Waste in Time and the Radioactivity of ObjectsEsther Leslie
- Phosphorus
- Dossier Overview
- 1. The Phosphorus ApparatusGregory T. CushmanZachary Caple
- 2. The Criticality of Phosphorus.
Data, Peaks & PoliticsOliver GantnerArno Rosemarin
- 3. Rifts, Cycles, and RecyclesZachary CapleScott KnowlesArno Rosemarin
- 4. Islands. Colonialism and GeopoliticsKaterina Teaiwa
- 5. Deserts. The Geopolitics of GeologyLino CamprubíTimothy Johnson
- Risk Equipment
- Dossier Overview
- A-Symmetry -
Algorithmic Finance and the Dark Side of the Efficient MarketGerald Nestler
- Financial Markets and the Technospheres They constituteKarin Knorr Cetina
- Impacts and Insurance: Climate Change Risk TransferScott KnowlesEberhard Faust
- Redeeming Urban Spaces:
The Ambivalence of Building a Pentecostal City in Lagos, NigeriaAsonseh Ukah
- Resilience as InfrastructureOrit Halpern
- Risk As Immaterial Raw MaterialFlorian Goldmann
- The Alternative Futures Approach –
Modelling the UnthinkableSebastian Vehlken
- The Risk Equipment Deserves More Credit: Modeling, Epistemic Opacity, and ImmersionMatthijs Kouw
- Spheres
- Dossier Overview
- Ecospheres: Model and Laboratory for Earth's EnvironmentSabine Höhler
- Sensing Air and Generating Worlds of DataJennifer Gabrys
- Strange-ing: Between Wonder and the UncannyRohini Devasher
- The Origin of the Idea of Material and Life Cycles in the Ancient Cosmos of Concentric SpheresPietro Daniel Omodeo
- The Terrestrial Is Not the GlobeBruno Latour
- Vladimir Vernadsky and the Co-evolution of the Biosphere, the Noosphere, and the TechnosphereGiulia RispoliJacques Grinevald
- Substances
- Dossier Overview
- Addiction, a Technology Mediating China and EuropePaul Boshears
- Anthropocene in the CellFlavio D'AbramoHannah Landecker
- Love Pill:
Oxytocin or Emotional Labor?Elvia Wilk
- Pharmocracy: Access and CareKaushik Sunder Rajan
- The Chemist and the BreacherBeate Geissler and Oliver Sann
- Toxic Sexes: Perverting Pollution and Queering Hormone DisruptionMalin Ah-KingEva Hayward
- Trauma
- Dossier Overview
- FlatWorld - A document of real/virtual trauma in the TechnosphereLucy Suchman
- On ASMRClaire Tolan
- Sleeping in Public, Working Like BabiesAnna Zett
- Sound and PainJosh Berson
- The Alien Hand of the Technosphere. Kurt Goldstein and the Trauma of Intelligent MachinesMatteo Pasquinelli
- The Free SeaLaura McLeanEle CarpenterHanna HusbergS. Ayesha Hameed
- Trauma of Machines That We Make Love to Machines?Rana Dasgupta
- Traumasphere, Thinking through Commodity ViolenceS. Løchlann Jain
- continent. inter-view:
Arno Rosemarin on disconcerting technical systemsArno Rosemarin
- Trust
- Dossier Overview
- Biopolitics of Trust in the Technosphere: A Look at Surrogacy, Labor, and FamilyKalindi Vora
- Contra Diction.
Speech Against ItselfLawrence Abu Hamdan
- Financialization as a ParodyAnna Echterhölter
- Pharmocracy: Access and CareKaushik Sunder Rajan
- The Abolition of Market DependencyNick Srnicek
- The Byzantine Generalization Problem: Subtle Strategy in the Context of Blockchain GovernanceKei Kreutler
- The Rise of the Planetary Labor Market—and What It Means for the Future of WorkMark Graham
- Tokens: A Rorschach TestBenjamin Bratton

- Lawrence Abu Hamdan
- Babak Afrassiabi
- Malin Ah-King
- Memo Akten
- Jamie Allen
- S. Ayesha Hameed
- Sammy Baloji
- Subhankar Banerjee
- On Barak
- Anil Bawa-Cavia
- Etienne Benson
- Josh Berson
- Jeremy Bolen
- Paul Boshears
- Benjamin Bratton
- Axel Braun
- Keith Breckenridge
- François Bucher
- Lino Camprubí
- Zachary Caple
- Ele Carpenter
- Andrew Chubb
- Louis Chude-Sokei
- Amy Cimini
- Claire Colebrook
- Flavio D'Abramo
- Ana Dana Beroš
- Pietro Daniel Omodeo
- Rana Dasgupta
- Filip De Boeck
- Seth Denizen
- Rohini Devasher
- Jonathan Donges
- Design Earth
- Keller Easterling
- Anna Echterhölter
- David Edgerton
- Technosphere Editorial
- Sasha Engelmann
- Lois Epstein
- Eberhard Faust
- Jennifer Gabrys
- Elaine Gan
- Oliver Gantner
- Beate Geissler and Oliver Sann
- Florian Goldmann
- Mark Graham
- Jacques Grinevald
- Johan Gärdebo
- Orit Halpern
- Eva Hayward
- Gabrielle Hecht
- Gerda Heck
- Florian Hecker
- Carola Hein
- Julian Henriques
- Hanna Husberg
- Sabine Höhler
- Erich Hörl
- Timothy Johnson
- Peter K. Haff
- Bernd Kasparek
- Nikos Katsikis
- Laleh Khalili
- Axel Kleidon
- Alexander Klose
- Karin Knorr Cetina
- Scott Knowles
- Nile Koetting
- Nicole Koltick
- Nik Kosmas
- Matthijs Kouw
- Matija Kralj
- Kei Kreutler
- Lars Kulik
- Richard L. Hindle
- Hannah Landecker
- Brian Larkin
- Bruno Latour
- Manfred Laubichler
- John Law
- Yoneda Lemma
- Esther Leslie
- George Lewis
- S. Løchlann Jain
- Donald MacKenzie
- Stefan Maier
- Chowra Makaremi
- Annapurna Mamidipudi
- Laura McLean
- Eden Medina
- Anne-Sophie Milon
- Paul N. Edwards
- Gerald Nestler
- Huiying Ng
- Daniel Niles
- James P. M. Syvitski
- Luciana Parisi
- Lisa Parks
- Matteo Pasquinelli
- Karen Pinkus
- Giulia Rispoli
- Sophia Roosth
- Arno Rosemarin
- Rafico Ruiz
- Kim Rygiel
- Dorion Sagan
- Isabelle Saint-Saëns
- Birgit Schneider
- Sever
- Jens Soentgen
- C Spencer Yeh
- Nick Srnicek
- Lizzie Stark
- Carolyn Steel
- Benjamin Steininger
- Lucy Suchman
- Kaushik Sunder Rajan
- Jenna Sutela
- Bronislaw Szerszynski
- Elisa T. Bertuzzo
- Gregory T. Cushman
- Nasrin Tabatabai
- Ksenia Tatarchenko
- Katerina Teaiwa
- Terre Thaemlitz
- Jol Thomson
- Claire Tolan
- John Tresch
- Etienne Turpin
- Asonseh Ukah
- Underworlds
- Sebastian Vehlken
- Vladimir Vernadsky
- Ben Vida
- Davor Vidas
- Kalindi Vora
- Jennifer Walshe
- Hannes Wiedemann
- Elvia Wilk
- Cary Wolfe
- Andrew Yang
- Jan Zalasiewicz
- Anna Zett
- Sander van der Leeuw
- Liv Østmo
Forensic Architecture / Goldsmiths, University of London
Stockholm University
Goldsmiths, University of London
Critical Media Lab Basel FHNW/ NSCAD, Halifax
Goldsmiths, University of London
University of New Mexico
Tel Aviv University
University of Pennsylvania
Hubbub / Max Planck Intitute for Human Cogntive and Brain Science
School of the Art Institute of Chicago
Ernest G. Welch School of Art and Design / Georgia State University
University of California, San Diego / Strelka Institute for Media, Architecture and Design, Moscow
Wits Insitute for Social and Economic Research
Max Planck Institute for the History of Science Berlin
University of California Santa Cruz
Goldsmiths, University of London
University of Western Australia
University of Washington, Seattle
University of California, San Diego
Penn State University
Max Planck Institute for the History of Science, Berlin
Ca’ Foscari University, Venice / Max Planck Institute for the History of Science, Berlin
University of Leuven
Stockholm Resilience Centre and Potsdam Institute for Climate Impact Research
Yale University
University of Vienna
King’s College London
HKW
Center for GeoHumanities, Royal Holloway, University of London
The Wilderness Society
Munich Re
Goldsmiths, University of London
University of Southern California and Aarhus University Research on the Anthropocene (AURA)
Resource Strategy, University of Augsburg
University of Illinois at Chicago / School of the Art Institute of Chicago
Potsdam University
Oxford Internet Institute and Alan Turing Institute, London
Graduate Institute of International and Development Studies, Geneva
Enviornmental Humanites Laboratory / Royal Institute of Technology
Concordia University, Montréal
University of Arizona, Tucson
Stanford University / Center for International Security and Cooperation
American University in Cairo
Delft University of Technology
Goldsmiths, University of London
KTH Royal Institute of Technology, Stockholm
University of Lüneburg / Digital Culture Research Lab
University of Georgia
Duke University, North Carolina
University of Luxembourg, Esch-sur-Alzette
SOAS, University of London
Max Planck Institute for Biogeochemistry
University of Chicago
Drexel University
Drexel University, Philadelphia
Rathenau Instituut, The Hague
University of California, Berkeley
University of California, Los Angeles
Barnard College, Columbia University
Sciences Po, Paris
Arizona State University / Global Biosocial Complexity Initiative
Open University, Milton Keynes
Birkbeck, University of London
Columbia University, New York
Stanford University Humanities Center
University of Edinburgh
National Center for Scientific Research, École des Hautes Études en Sciences Sociales, Paris
Max Planck Institute for the History of Science, Berlin
Indiana University, Bloomington
Stanford University / Program in Science, Technology, and Society
Research Institute for Humanity and Nature, Kyoto
University of Colorado Boulder
Goldsmiths, University of London
MIT
Cornell University
Max Planck Institute for the History of Science, Berlin
Harvard University, Cambridge, MA
Stockholm Environment Institute
University of Alberta
Balsillie School of International Affairs, Waterloo, Canada
University of Potsdam
Speculative Design Project
University of Augsburg
King's College London
Technical University of Berlin / Cluster of Excellence “Unifying Systems of Catalysis”
University of Lancaster
Chicago Center for Contemporary Theory, University of Chicago
University of Kansas
Global Studies Institute, Geneva University
Australian National University
University of Pennsylvania
anexact office and Massachusetts Institute of Technology
University of Cape Town
MIT
Leuphana University Lüneburg
Fridtjof Nansen Institute, Lysaker
Feminist Research Institute, University of California, Davis
Rice University, Houston
School of the Art Institute of Chicago
University of Leicester / Anthropocene Working Group
School of Sustainability, Arizona State University
Sámi University of Applied Sciences, Kautokeino
- Anthropotechnics
- Physically ingrained practices and routines are a subtle yet decisive precondition for perceiving, coherently grasping, and adequately responding to the more-than-human dynamics of a global environment in transition.
- Anthropotechnics for the AnthropoceneJohn Tresch
- Contra Diction.
Speech Against ItselfLawrence Abu Hamdan
- Dancing (the) TechnosphereTechnosphere Editorial
- Larp as TechnologyLizzie Stark
- On Anthropotechnics and Physical PracticeNik Kosmas
- Potency and Partial Knowledge.
An ExerciseJeremy BolenAndrew Yang
- Worshipping Along the Routes of Migration: Religion as InfrastructureGerda Heck
- Arctic
- How has the Arctic region, a highly engineered and technically activated space, become a cold laboratory of the technosphere and its reach? This dossier looks at the multiple historical and current registers of contention over the future of a dramatically changing region.
- Living Arctic InfrastructuresRafico Ruiz
- On Land and Lakes: Colonizing the NorthJohn LawLiv Østmo
- Sever. Pre-emptive Strategy for an Open ArcticSever
- Sitting On Top of the World: Meridional Media, Arctic Condescension, and Northern TechniquesJamie Allen
- The Arctic Upside DownKaren Pinkus
- The Fight for Alaska's Arctic Has Just BegunSubhankar BanerjeeLois Epstein
- The Lena Is Worthy of Baikal: Defining Remoteness Across the North and the EastKsenia Tatarchenko
- Borders
- borders are about drawing lines; they are complex organizational ecologies built on inbuilt and intentional forces. For this dossier, we will explore the many direct and indirect technological means used to enforce rigid border structures.
- Citizenship and Technologies of BorderingKim Rygiel
- Deportation and the Technification of Force: Violence in DemocracyChowra Makaremi
- GeotraumaMatija KraljAna Dana Beroš
- On the Operation of Border RegimesBernd KasparekIsabelle Saint-Saëns
- Worshipping Along the Routes of Migration: Religion as InfrastructureGerda Heck
- Creolized Technologies
- This dossier looks at how these local particularities and relations resonate as écho-mondes that reflect back local dynamics, modulating technological usage in such a manner that the technologies themselves are irreversibly transformed
- A Caribbean Taste of Technology: Creolization and the Ways-of-Making of the Dancehall Sound SystemJulian Henriques
- Creole TechnologiesDavid Edgerton
- Creolized Technologies of DemoralizationElisa T. Bertuzzo
- Memories of the Yagán: The Chilean Automobile for the PeopleEden Medina
- Race and Technology: A Creole HistoryLouis Chude-Sokei
- The Shipworm and the
TelegraphOn Barak
- Earth
- What is the fundamental idea behind the concept of the technosphere within its original context as an emergent component of the Earth system? What does it mean when technics create a system potent enough to intervene in and rival other geospheres?
- A Legacy of the TechnosphereJan ZalasiewiczAnne-Sophie Milon
- Möbius Trip. The Technosphere and Our Science Fiction RealityDorion Sagan
- Sensing Air and Generating Worlds of DataJennifer Gabrys
- Technosphere and TechnoecologyErich HörlPeter K. Haff
- The Biosphere in the Cosmic MediumVladimir Vernadsky
- The Virtual FieldEtienne Benson
- Ve Vm Vt. The Ideal Cosmic MessengersSasha EngelmannJol Thomson
- WhistlerNile Koetting
- continent. inter-view:
Bronislaw Szerszynski on the TechnosphereBronislaw Szerszynski
- Human
- Toying with notions traditionally used to define the exceptionalism of the human species (Homo: sapiens, faber, ludens, economicus), this dossier pursues the muddling effects of the technosphere
- EmbeddedFrançois BucherLars Kulik
- GrindersHannes Wiedemann
- Instrumentality, or the Time of Inhuman ThinkingLuciana Parisi
- Is the Anthropocene …
A Doomsday Device?Cary WolfeClaire Colebrook
- Phenomenal MachinesNicole Koltick
- Race and Technology: A Creole HistoryLouis Chude-Sokei
- Solid/Solipsism RemedyJenna Sutela
- Somewhere, Somehow.
A Co-Evolution Story.Jonathan DongesSeth Denizen
- The Inclosure of ReasonAnil Bawa-Cavia
- Infrastructure
- infrastructure is both the epistemic and physical skeleton upon which the technosphere grows and proliferates. It provides the reasons behind how things are organized and makes such an organization possible in some sort of fixed capacity
- 1333AD, Port of Aden, YemenLaleh Khalili
- Ambient Infrastructures. Generator Life in NigeriaBrian Larkin
- Biometric CapitalismKeith Breckenridge
- Container Love, and FearAlexander Klose
- Infrastructure and AffectLisa Parks
- Larp as TechnologyLizzie Stark
- Sensing Air and Generating Worlds of DataJennifer Gabrys
- Technosphere VerticalityJohan Gärdebo
- Telecommunications.
A micro historyBirgit Schneider
- The Microwave Tower of the NYSE and the Physicality of FinanceDonald MacKenzie
- The Tower. A Concrete UtopiaFilip De BoeckSammy Baloji
- The Virtual FieldEtienne Benson
- UnderworldsUnderworlds
- Urban PornKeller Easterling
- Land & Sea
- this dossier explores the recomposition of interconnected economies, legal frameworks, and environments along the liminal spaces that blend land and sea into one another
- Changes in Fluvial Systems, River Sediments and DeltasJames P. M. Syvitski
- China’s “Blue Territory” and the Technosphere in Maritime East AsiaAndrew Chubb
- Jakarta: A Colonial Water-Management Fantasy ParkEtienne Turpin
- Kish, an Island Indecisive by DesignBabak AfrassiabiNasrin Tabatabai
- On Land and Lakes: Colonizing the NorthJohn LawLiv Østmo
- Port Cities: Nodes in the Global Petroleumscape between Sea and LandCarola Hein
- Rivers, Coasts, and the Geographical Dimensions of Patent InnovationRichard L. Hindle
- The Risk Equipment Deserves More Credit: Modeling, Epistemic Opacity, and ImmersionMatthijs Kouw
- Towards an Understanding of Anthropocene LandscapesAxel Braun
- When the Sea Begins to Dominate the LandDavor Vidas
- Machine Listening
- what if behind these displays of streamlined functionalism, the advent of machine listening might also show that machines listen far differently than humans do?
- 1. WaveNet: On Machine and Machinic ListeningStefan Maier
- 2. ULTRACHUNKJennifer WalsheMemo Akten
- 3. Couture Cosmetique: Transgendered electroacoustique symptomatic of the need for a cultural makeover (Or... What's behind all that foundation?)Terre Thaemlitz
- 4. Heteroglossic RiotBen Vida
- 5. Rainbow FamilyGeorge Lewis
- 6. 1935Florian Hecker
- 7. Mei-Jia & Ting-Ting & Chih-Fu & Sin-JiC Spencer Yeh
- 8. Supreme Connections Meets Video City in Maryanne Amacher’s Intelligent LifeAmy Cimini
- 9. Anti-WorldsYoneda Lemma
- Materials
- the entire material world has been turned into a resource to be manipulated, consumed, or reordered. It is the industrialization of this relationship between humankind and all matter that has contributed decisively to creating the technosphere.
- A Recipe for Crafting Color: The Revival of Natural Dyeing in South IndiaAnnapurna Mamidipudi
- Explosives: Prime Movers of the AnthropoceneJens Soentgen
- Latent LifeSophia Roosth
- Phenomenal MachinesNicole Koltick
- The Material OrderSander van der LeeuwDaniel Niles
- To See a World in a Grain of Rice:
Temporalities of a Flowering Grass and the Great AccelerationElaine Gan
- Waste in Time and the Radioactivity of ObjectsEsther Leslie
- Metabolic Systems
- This dossier explores how technological metabolisms are built and maintain themselves as evolutionary systems
- Georama of TrashDesign Earth
- How the Technosphere Can Make the Earth More ActiveAxel Kleidon
- In the Sphere of Chemical TechnologyBenjamin Steininger
- Operational Landscapes and the Planetary Thünen TownNikos Katsikis
- Sitopia: The Power of Thinking Through FoodCarolyn Steel
- Soil’s metabolic rift: Metabolising hope, interrupting the mediumHuiying Ng
- Solid/Solipsism RemedyJenna Sutela
- Taking on the Technosphere: A Kitchen DebateGabrielle HechtPaul N. Edwards
- The Growth and Differentiation of Metabolism: Extended Evolutionary Dynamics in the TechnosphereManfred Laubichler
- Waste in Time and the Radioactivity of ObjectsEsther Leslie
- Phosphorus
- The Phosphorus Apparatus tells the story of that circulation ‒ by tracing a network of technical, earthly, and cultural mediations by following the dramaturgies of modern civilization through past, present, and future.
- 1. The Phosphorus ApparatusGregory T. CushmanZachary Caple
- 2. The Criticality of Phosphorus.
Data, Peaks & PoliticsOliver GantnerArno Rosemarin
- 3. Rifts, Cycles, and RecyclesZachary CapleScott KnowlesArno Rosemarin
- 4. Islands. Colonialism and GeopoliticsKaterina Teaiwa
- 5. Deserts. The Geopolitics of GeologyLino CamprubíTimothy Johnson
- Risk Equipment
- Risk equipment is the way in which we plan for contingency. From financial tools to scenario modeling to concrete landscaping, the planning apparatuses explored in this dossier attempt to stabilize the unstable through projecting information in anticipation of possible hazards
- A-Symmetry -
Algorithmic Finance and the Dark Side of the Efficient MarketGerald Nestler
- Financial Markets and the Technospheres They constituteKarin Knorr Cetina
- Impacts and Insurance: Climate Change Risk TransferScott KnowlesEberhard Faust
- Redeeming Urban Spaces:
The Ambivalence of Building a Pentecostal City in Lagos, NigeriaAsonseh Ukah
- Resilience as InfrastructureOrit Halpern
- Risk As Immaterial Raw MaterialFlorian Goldmann
- The Alternative Futures Approach –
Modelling the UnthinkableSebastian Vehlken
- The Risk Equipment Deserves More Credit: Modeling, Epistemic Opacity, and ImmersionMatthijs Kouw
- Spheres
- How do we approach, let alone understand, this shape-giving notion of a sphere embodying the technological condition of our planet? This dossier seeks to circumscribe and visualize the spatial forms and parameters now increasingly captured by the accidental megastructure of technics.
- Ecospheres: Model and Laboratory for Earth's EnvironmentSabine Höhler
- Sensing Air and Generating Worlds of DataJennifer Gabrys
- Strange-ing: Between Wonder and the UncannyRohini Devasher
- The Origin of the Idea of Material and Life Cycles in the Ancient Cosmos of Concentric SpheresPietro Daniel Omodeo
- The Terrestrial Is Not the GlobeBruno Latour
- Vladimir Vernadsky and the Co-evolution of the Biosphere, the Noosphere, and the TechnosphereGiulia RispoliJacques Grinevald
- Substances
- This dossier explores the biotechnical infrastructures that are increasingly reorganizing the boundaries of biochemical life on Earth.
- Addiction, a Technology Mediating China and EuropePaul Boshears
- Anthropocene in the CellFlavio D'AbramoHannah Landecker
- Love Pill:
Oxytocin or Emotional Labor?Elvia Wilk
- Pharmocracy: Access and CareKaushik Sunder Rajan
- The Chemist and the BreacherBeate Geissler and Oliver Sann
- Toxic Sexes: Perverting Pollution and Queering Hormone DisruptionMalin Ah-KingEva Hayward
- Trauma
- How is the technosphere not only inscribed into the surface of the Earth but also in individuals, and how does it determine and shape the behavior of collectives? What kinds of injuries and frictions result from the engineering of our environments – and ourselves – along a complex machinery of instruments, techniques, and simulations?
- FlatWorld - A document of real/virtual trauma in the TechnosphereLucy Suchman
- On ASMRClaire Tolan
- Sleeping in Public, Working Like BabiesAnna Zett
- Sound and PainJosh Berson
- The Alien Hand of the Technosphere. Kurt Goldstein and the Trauma of Intelligent MachinesMatteo Pasquinelli
- The Free SeaLaura McLeanEle CarpenterHanna HusbergS. Ayesha Hameed
- Trauma of Machines That We Make Love to Machines?Rana Dasgupta
- Traumasphere, Thinking through Commodity ViolenceS. Løchlann Jain
- continent. inter-view:
Arno Rosemarin on disconcerting technical systemsArno Rosemarin
- Trust
- This dossier explores how technology influences the establishment of trust relationships in our sociotechnical world by negotiating the criteria we rely on to create trust in institutional structures, knowledge, and practices.
- Biopolitics of Trust in the Technosphere: A Look at Surrogacy, Labor, and FamilyKalindi Vora
- Contra Diction.
Speech Against ItselfLawrence Abu Hamdan
- Financialization as a ParodyAnna Echterhölter
- Pharmocracy: Access and CareKaushik Sunder Rajan
- The Abolition of Market DependencyNick Srnicek
- The Byzantine Generalization Problem: Subtle Strategy in the Context of Blockchain GovernanceKei Kreutler
- The Rise of the Planetary Labor Market—and What It Means for the Future of WorkMark Graham
- Tokens: A Rorschach TestBenjamin Bratton
- Lawrence Abu Hamdan
- published contributions
- Babak Afrassiabi
- Babak Afrassiabi is an artist who works both in Iran and the Netherlands. Since 2004, he has collaborated with Nasrin Tabatabai on various joint projects and the publication of the bilingual magazine Pages (Farsi and English). Their work seeks to articulate the undecidable space between art and its historical conditions, including the recurring question of the place of the archive in defining the juncture between politics, history, and the practice of art. The artists’ work has been presented internationally in various solo and group exhibitions and they have been tutors at the Jan Van Eyck Academie, Maastricht (2008–13), and Erg, école supérieure des arts, Brussels (2015–).
- published contributions
- Malin Ah-King
- , Los Angeles; Macquarie University, Sydne
- published contributions
- Memo Akten
- . He is currently a PhD candidate at Goldsmiths, University of London, where he is researching artificial intelligence, machine learning, and expressive human-ma
- published contributions
- Jamie Allen
- ics engineer, a polymer chemist, and a designer with the American Museum of Natural History, New York.
- published contributions
- S. Ayesha Hameed
- Dr. S. Ayesha Hameed is a Lecturer in Visual Cultures and the Joint Programme Leader in Fine Art and History of Art Research Fellow in Forensic Architecture at Goldsmiths, London. She received her PhD in Social and Political Thought at York University, Canada in 2008
- published contributions
- Sammy Baloji
- published contributions
- Subhankar Banerjee
- e Tipping Point (2012), and The Routledge Companion to Contemporary Art, Visual Culture, a
- published contributions
- On Barak
- On Barak is a social and cultural historian of science and technology in non-Western settings. He has been a senior lecturer in the Department of Middle Eastern and African History at Tel Aviv University since 2012. Prior to this, he was a member of the Princeton Society of Fellows. In 2009, Barak received a joint PhD in History and Middle Eastern Studies from New York University. His most recent book is On Time: Technology and Temporality in Modern Egypt (University of California Press, 2013), and his current publication project, Coalonialism: Energy and Empire before the Age of Oil, is funded by a European Union Marie Curie Award and an Israel Science Foundation Grant.
- published contributions
- Anil Bawa-Cavia
- Anil Bawa-Cavia is a computer scientist with a background in machine learning. He runs STDIO, a speculative software studio. His practice engages with algorithms, protocols, encodings, and other software artifacts and his doctoral research at the Center for Advanced Spatial Analysis (CASA) at University College London was on complex networks in urbanism. He is a founding member of Call & Response, a sonic arts collective and gallery space in London, and a member of the New Centre for Research & Practice.
- published contributions
- Etienne Benson
- published contributions
- Josh Berson
- published contributions
- Jeremy Bolen
- published contributions
- Paul Boshears
- hy, aesthetics, and contemporary French and German
- published contributions
- Benjamin Bratton
- for Media, Architecture and Design, Moscow. Bratton is also Professor of Digital Design at the Eur
- published contributions
- Axel Braun
- Axel Braun studied photography at the Folkwang University of the Arts, Essen, and fine arts at the École nationale supérieure des Beaux-Arts de Paris. His artistic research deals with controversial infrastructure projects, tautology as an attempt to understand reality, and failed utopias in art and architecture. Currently, he is pursuing the long-term project Towards an Understanding of Anthropocene Landscapes. Recently exhibited works include Some Kind of Opposition (2016) at Galeria Centralis, Budapest, and Dragonflies drift downstream on a river (2015) at Kunstmuseum Bochum.
- published contributions
- Keith Breckenridge
- published contributions
- François Bucher
- s, focusing on ethical and aesthetic problems of cinema and television, and more recently on the image as an interdimensional field. His work has been exhibited at
- published contributions
- Lino Camprubí
- Lino Camprubí is a Research Scholar at the Max Planck Institute for the History of Science in Berlin.
- published contributions
- Zachary Caple
- Zachary Caple is a Ph.D. candidate in Cultural Anthropology at the University of California Santa Cruz.
- published contributions
- Ele Carpenter
- Dr. Ele Carpenter is a senior lecturer in curating at Goldsmiths, London. Her curatorial practice responds to interdisciplinary socio-political contexts such as the nuclear economy and the relationship between craft and code.
- published contributions
- Andrew Chubb
- Andrew Chubb is a PhD candidate at the University of Western Australia conducting research on the relationship between Chinese public opinion and government policy in the South China Sea. His articles have appeared in the Journal of Contemporary China, Pacific Affairs, East Asia Forum, and Information, Communication & Society. His blog, South Sea Conversations (southseaconversations.wordpress.com), provides translations and analysis of Chinese discourse on the South and East China Sea issues.
- published contributions
- Louis Chude-Sokei
- Louis Chude-Sokei is a writer and scholar currently teaching in the English Department at the University of Washington, Seattle. His academic interests range from West African, Caribbean, and American literary and cultural studies to a particular focus on sound, technology, and performance. His literary and public work focuses on immigration and black-on-black cultural contacts, conflicts, and exchanges. Chude-Sokei is the author of the award-winning book The Last “Darky”: Bert Williams, Black-on-Black Minstrelsy, and the African Diaspora (2006) and The Sound of Culture: Diaspora and Black Technopoetics (2016).
- published contributions
- Amy Cimini
- be starting new projects on sonic histories of borderw
- published contributions
- Claire Colebrook
- Claire Colebrook is a professor of English at Penn State University. Her areas of specialization are contemporary literature, visual culture, and theory and cultural studies. She has written articles on poetry, literary theory, queer theory, and contemporary culture. Colebrook is the co-editor of the series Critical Climate Change, published by Open Humanities Press, and a member of the advisory board of the Institute for Critical Climate Change. She recently completed two books on extinction for Open Humanities Press, Death of the PostHuman and Sex after Life (both 2014), and with Tom Cohen and J. Hillis Miller co-authored Twilight of the Anthropocene Idols (2016).
- published contributions
- Flavio D'Abramo
- His current
- published contributions
- Ana Dana Beroš
- chitect and curator focused on creating uncertain, fragile environments that catalyze social chan
- published contributions
- Pietro Daniel Omodeo
- Berlin. His research focuses on science, philosophy,
- published contributions
- Rana Dasgupta
- published contributions
- Filip De Boeck
- Filip De Boeck is actively involved in teaching, promoting, coordinating and supervising research in and on Africa at the Institute for Anthropological research in Africa at the U
- published contributions
- Seth Denizen
- Seth Denizen is a researcher and design practitioner trained in landscape architecture and evolutionary biology. Since completing research on the sexual behavior and evolutionary ecology of small Trinidadian fish, his work has focused on the aesthetics of scientific representation, madness, and public parks, the design of t
- published contributions
- Rohini Devasher
- e” terrains, cons
- published contributions
- Jonathan Donges
- Jonathan Donges is a postdoctoral researcher who holds a joint position at the Stockholm Resilience Centre (as Stordalen Scholar) and the Potsdam Institute for Climate Impact Research. He studies planetary boundaries and social dynamics in the Earth system from a complex dynamical system perspective. At Potsdam, he is Co-head of the flagship COPAN (Coevolutionary Pathways) project (www.pik-potsdam.de/copan). His published research includes work on complex network theory, dynamical systems theory, and time series analysis, with a focus on their application to our understanding of past and present climate variability and its interactions with humankind on planet Earth.
- published contributions
- Design Earth
- ollaborative architectural practice led by El Hadi Jazairy
- published contributions
- Keller Easterling
- published contributions
- Anna Echterhölter
- Technical University, Berlin,
- published contributions
- David Edgerton
- David Edgerton is Hans Rausing Professor of the History of Science and Technology and a professor of modern British history at King’s College London. After teaching at the University of Manchester, he became the founding director of the Centre for the History of Science, Technology and Medicine at Imperial College London (1993–2003), and moved along with the centre to King’s College London in August 2013. He is the author of many works, including The Shock of the Old: Technology and Global History since 1900 (2007), which argues for and exemplifies new ways of thinking about the material constitution of modernity.
- published contributions
- Technosphere Editorial
- Us peoples
- published contributions
- Sasha Engelmann
- Sasha Engelmann is a geographer exploring creative experiments with atmosphere, the elemental, and the limits of sensing.
- published contributions
- Lois Epstein
- stein is Arctic Program Director at the Wilderness Society an American land conservation non-profit. A licensed engineer, she has served on a number of federal advisory committees, including a National Academy of Sciences committee studying oil and gas regulations, and, for twelve years, a committee focusing on oil pipeline safety. Epstein holds a Master of Civil Engineering with a specialization in environme
- published contributions
- Eberhard Faust
- Eberhard Faust received a PhD in the humanities from Heidelberg University, after which he studied geoecology and environmental sciences, specializing in meteo
- published contributions
- Jennifer Gabrys
- Jennifer Gabrys is Reader in the Department of Sociology at Goldsmiths, University of London, and Principal Investigator on the ERC-funded project, "Citizen Sense." Her publications include Digital Rubbish: A Natural History of Electronics (University of Michigan Press, 2011); and Program Earth: Environmental Sensing Technology and the Making of a Computational Planet (University of Minnesota Press, forthcoming).
- published contributions
- Elaine Gan
- ne (AURA) in Denmark. Gan plays at the intersection of digital media arts, environmental humanities, and science studies and is interested in
- published contributions
- Oliver Gantner
- Dr. Oliver Gantner is research associate for Resource Strategy at Augsburg University. He conducts projects related to resource efficiency, life-cycle assessment and environmental strategies.
- published contributions
- Beate Geissler and Oliver Sann
- p since 19
- published contributions
- Florian Goldmann
- Florian Goldmann is a Berlin-based artist and a PhD candidate at the DFG Research Training Center Visibility and Visualisation – Hybrid Forms of Pictorial Knowledge as well as at the Brandenburg Center for Media Studies, both Potsdam University. His research focus is the utilization of models as a means of both commemorating and predicting catastrophe. In 2015, he took part in the Third UN World Conference on Disaster Risk Reduction (WCDRR) in Sendai, Japan. Goldmann is one of the founders of the research collective STRATAGRIDS and the author of Flexible Signposts to Coded Territories (2012), an analysis of football hooligan graffiti in Athens as a system of fluid signage.
- published contributions
- Mark Graham
- raphy at the Oxford Internet Institute and a facu
- published contributions
- Jacques Grinevald
- esearch develops around the figures of the French military engi
- published contributions
- Johan Gärdebo
- Johan Gärdebo is a PhD candidate at the Royal Institute of Technology affiliated to the Environmental Humanities Laboratory (EHL). H
- published contributions
- Orit Halpern
- Orit Halpern is a Strategic Hire in Interactive Design and an associate professor in the Department of Sociology and Anthropology at Concordia University, Montreal. Her work bridges the histories of science, computing, and cybernetics with design and art practice. She is also a co-director of the Speculative Life Research Cluster, Montreal, a laboratory situated at the intersection of art and life sciences, architecture and design, and computational media (www.speculativelife.com). Her recent monograph, Beautiful Data (2015), is a history of interactivity, data visualization, and ubiquitous computing. www.orithalpern.net
- published contributions
- Eva Hayward
- She has recently
- published contributions
- Gabrielle Hecht
- the board of Andra, France’s national radioactive waste management agency
- published contributions
- Gerda Heck
- gration and border regimes, urban studies, transnational migration, migrant networks, religion,
- published contributions
- Florian Hecker
- dio 3 as the broadcaster’s first ever live binaural broadcast. Recent major exhibitions
- published contributions
- Carola Hein
- Carola Hein is a professor of the history of architecture and urban planning in the Architecture Department at Delft University of Technology. She has published widely on topics in contemporary and historical architectural and urban planning, notably that of Europe and Japan. Her current research interests include transmission of architectural and urban ideas along international networks, focusing specifically on port cities, and the global architecture of oil. Her books include Port Cities: Dynamic Landscapes and Global Networks (2011), Cities, Autonomy, and Decentralization in Japan (2006), and The Capital of Europe: Architecture and Urban Planning for the European Union (2004).
- published contributions
- Julian Henriques
- Julian Henriques is the convener of the MA in Script Writing and Director of the Topology Research Unit in the Department of Media and Communications at Goldsmiths, University of London. Prior to this, he ran the film and television department at the Caribbean Institute of Media and Communication (CARIMAC) at the University of the West Indies, Kingston, Jamaica. His credits as a writer and director include the reggae musical feature film Babymother (1998) and as a sound artist, Knots & Donuts, exhibited at Tate Modern in 2011. Henriques researches street cultures and technologies and his publications include Changing the Subject: Psychology, Social Regulation, and Subjectivity (1998), Sonic Bodies: Reggae Sound Systems, Performance Techniques, and Ways of Knowing (2011), and Sonic Media (forthcoming).
- published contributions
- Hanna Husberg
- Hanna Husberg is a Stockholm-based artist. She graduated from ENSB-A in Paris in 2007 and is currently a PhD in Practice candidate at the Academy of Fine Arts, Vienna.
- published contributions
- Sabine Höhler
- tion from TU Darmstadt in the history of science, technology, and the environment. Her researc
- published contributions
- Erich Hörl
- published contributions
- Timothy Johnson
- ???
- published contributions
- Peter K. Haff
- published contributions
- Bernd Kasparek
- ation borde
- published contributions
- Nikos Katsikis
- Harvard Graduate School of Design (GSD) and is cu
- published contributions
- Laleh Khalili
- published contributions
- Axel Kleidon
- penden
- published contributions
- Alexander Klose
- Dr. Alexander Klose studied History, Law, Philosophy, Art, and Cultural Studies. From 2005-07 he held a scholarship at Bauhaus Universität Weimar for his PhD project on standardized containers used in transport as one of the leading material media in the 20th century. Between 2009 and 2014 he worked as a research associate and programme developer at Kulturstiftung des Bundes. In 2015 in the forefront of COP 21, he co-curated Blackmarket for Useful Knowledge and Non-Knowledge No. 18 – On Becoming Earthlings: 150 dialogues and exercises in shrinking and expanding the Human at Musée de l'Homme, Paris. His latest publication is: The Container Principle. How a box changes the way we think (2015).
- published contributions
- Karin Knorr Cetina
- t Distinguished Servi
- published contributions
- Scott Knowles
- Scott Knowles is associate professor in the Department of History at Drexel University.
- published contributions
- Nile Koetting
- published contributions
- Nicole Koltick
- Nicole Koltick is an assistant professor in the Westphal College of Media Arts & Design at Drexel University, Philadelphia. She is Founding Director of the Design Futures Lab at Westphal College, which is currently pursuing design research to stimulate debate on the potential implications of emerging technological and scientific developments within society. Koltick’s practice spans art, science, technology, design, and philosophy, and current work focuses on the philosophical, material, and relational implications of aesthetics as they intersect with emerging developments in computational creativity, artificially intelligent autonomous systems, robotics, and synthetic biological hybrids.
- published contributions
- Nik Kosmas
- published contributions
- Matthijs Kouw
- Matthijs Kouw joined the Rathenau Instituut, The Hague, in March 2016. He holds an MA in Philosophy and an MSc in Science and Technology Studies from the University of Amsterdam as well as a PhD from Maastricht University. In his PhD thesis, Kouw describes how and to what extent reliance on models can introduce vulnerabilities through the assumptions, uncertainties, and blind spots concomitant with modeling practice. He was employed as a postdoctoral researcher at the Netherlands Environmental Assessment Agency (PBL), during which time he acted as a member of the Dutch delegation for plenary sessions of the Intergovernmental Panel on Climate Change (IPCC).
- published contributions
- Matija Kralj
- part at t
- published contributions
- Kei Kreutler
- prediction market platforms and decentralized e
- published contributions
- Lars Kulik
- Lars Kulik studied biology at the Humboldt University of Berlin. He received his doctorate on the development of social behavior of rhesus monkeys at the University of Leipzig and the Max Planck Institute for Evolutionary Anthropology. He lives with his family in Berlin.
- published contributions
- Richard L. Hindle
- Richard L. Hindle is an assistant professor of landscape architecture and environmental planning at the University of California, Berkeley. His current research focuses on patent innovation in landscape related technologies, from large-scale mappings of riverine and coastal systems to detailed historical studies on the antecedents of vegetated architecture. His work explores the potential of new technological narratives and material processes to reframe theory, practice, and the production of landscape. Recent works include the articles “Levees That Might Have Been” (2015), and “Infrastructures of Innovation” in Scaling Infrastructure (MIT Center for Advanced Urbanism, 2016), and the exhibition Geographies of Innovation at UC Berkeley (2015).
- published contributions
- Hannah Landecker
- which looks at transformations of the metabolic
- published contributions
- Brian Larkin
- published contributions
- Bruno Latour
- e as well as a professor at the Karlsruhe Unive
- published contributions
- Manfred Laubichler
- l Biosocial Complexity Initiative, Arizona State University and a Professor at the Sant
- published contributions
- John Law
- hn Law was a professor of sociology at Keele University, Lancaster, and the Open University, Milton Keynes, and a co-director of the Economic and Social Researc
- published contributions
- Yoneda Lemma
- ents from one fiction to another. She has exhibited her work at V4ULT, Berlin; Le Cube, Par
- published contributions
- Esther Leslie
- t theories of aesthetics and culture, with a particular focus on the work of Walter Benjamin and Theodor Adorno. It deals with the poetics of science, European literary and visual modern
- published contributions
- George Lewis
- my of Arts and Letters, New York. He has been a member of the Association for the Advancement of Creative Musicians (AACM), Chicago, since 1971. Lewis’s work as composer, electronic performer, installa
- published contributions
- S. Løchlann Jain
- published contributions
- Donald MacKenzie
- published contributions
- Stefan Maier
- work has been presented by ULTIMA Oslo Contemporary Music Festival; Forecast Fest
- published contributions
- Chowra Makaremi
- d proces
- published contributions
- Annapurna Mamidipudi
- aditional craft in the contemporary world, particularly handloom weaving as embodied knowledge, and the politics of sustainable development. She participated in the
- published contributions
- Laura McLean
- Laura McLean is a curator, artist, and writer based in London. She is a graduate of Goldsmiths College and Sydney College of the Arts, where she later lectured. She has also studied at Alberta College of Art and Design, and the Universität der Künste Berlin.
- published contributions
- Eden Medina
- Eden Medina is an associate professor of informatics and computing, affiliated associate professor of law, and adjunct associate professor of history at Indiana University, Bloomington. Her research and teaching address the social, historical, and legal dimensions of our increasingly data-driven world, including the relationship of technology to human rights and free expression, the relationship between political innovation and technological innovation, and the ways that human and political values shape technological design. Medina’s writings also use science and technology as a way to broaden understandings of Latin American history and the geography of innovation. She is the author of Cybernetic Revolutionaries: Technology and Politics in Allende's Chile (2011) and the co-editor of Beyond Imported Magic: Essays on Science, Technology, and Society in Latin America (2014).
- published contributions
- Anne-Sophie Milon
- Anne-Sophie Milon is an artist and a freelance illustrator and animator working and living in Bristol, UK. After completing two Masters in Art, she has recently concluded the program of experimentation in Art and Politics at SciencesPo (SPEAP) in Paris.
- published contributions
- Paul N. Edwards
- rsity, as well as Professor of Information and History (Emeritus) at the University of Michigan. His research focuses on the history and po
- published contributions
- Gerald Nestler
- Gerald Nestler is an artist and writer who combines theory and post-disciplinary conversation with video, installation, performance, text, code, graphics, sound, and speech. He explores what he calls the derivative condition of contemporary social relations and its paradigmatic financial models, operations, processes, narratives, and fictions. He is currently working on an “aesthetics of resolution” that maps counterfictions and counterimaginations for “renegade activism,” which revolves around the demonstration as a combined artistic, technological, social, and political practice. Nestler holds a practice-based PhD from the Centre for Research Architecture at Goldsmiths, University of London.
- published contributions
- Huiying Ng
- an iterative
- published contributions
- Daniel Niles
- terial, millenary and momentary—that their knowledge takes, and, finally, the significance of this experience to our understanding of t
- published contributions
- James P. M. Syvitski
- James P. M. Syvitski is Executive Director of the Community Surface Dynamics Modeling System (CSDMS) at the University of Colorado Boulder. From 2011 to 2016, he chaired the International Council for Science’s International Geosphere-Biosphere Programme (IGBP), which provides essential scientific leadership and knowledge of the Earth system to help guide society toward a sustainable pathway during rapid global change. His specialty is the global flux of water and sediment (river and ocean borne) and its trends in the Anthropocene. He works at the forefront of computational geosciences, including sediment transport, land-ocean interactions, and Earth-surface dynamics.
- published contributions
- Luciana Parisi
- Luciana Parisi is Reader in Cultural Theory, Chair of the PhD program in Cultural Studies, and Co-director of the Digital Culture Unit at Goldsmiths, University of London. Her research focuses on cybernetics, information theory and computation, complexity and evolutionary theories, and the technocapitalist investment in artificial intelligence, biotechnology, and nanotechnology. Her books include Abstract Sex: Philosophy, Biotechnology and the Mutations of Desire (2004) and Contagious Architecture: Computation, Aesthetics, and Space (2013). She is currently researching the history of automation and the philosophical consequences of logical thinking in machines.
- published contributions
- Lisa Parks
- published contributions
- Matteo Pasquinelli
- published contributions
- Karen Pinkus
- w York. She is also a faculty fellow of the Atkinson Center for a Sustainable Future, Ithaca. Author of numerous publications in literary studies, Italian studies, critical theory, and environmental humanities, Pinkus is also Editor of the journal Diacritics. In her latest book, Fuel (2016), Pinkus thinks about issues crucial to climate ch
- published contributions
- Giulia Rispoli
- History of Science, Berlin. She investigates the antecedents of the Anthropocene concept from
- published contributions
- Sophia Roosth
- t when researchers are building new biological systems in order to investigate how biology works. She holds a PhD from the Massachuse
- published contributions
- Arno Rosemarin
- Rafico Ruiz
- afico Ruiz is Social Sciences and Humanities Research Council of Canada Banting Postdoctoral Fellow in the Department of Sociology at the University of Alberta, Edmonton. He studies the relationships between mediation and social space, particularly in the Arctic and subarctic; the cultural geographies of natural resource engagements; and
- published contributions
- Kim Rygiel
- f International Affairs in Waterloo, Canada. Her research focuses on border security, migration, and citizenship in North America and Europe. She investigates how citizens and non-citizens engage in citizenship practices and challenge notions
- published contributions
- Dorion Sagan
- published contributions
- Isabelle Saint-Saëns
- ion and sup
- published contributions
- Birgit Schneider
- published contributions
- Sever
- SEVER was developed as a speculative design project by Francesco Sebregondi, Alexey Platonov, Inna Pokazanyeva, and Ildar Iakubov during the New Normal postgraduate program at Strelka Institute for Media, Architecture and Design, Moscow. SEVER seeks to intervene into current Arctic debates by disturbing the landscape of the region’s possible futures
- published contributions
- Jens Soentgen
- l University in St. John’s, Canada and, since
- published contributions
- C Spencer Yeh
- contributing editor of BOMB. Recent exhibitions and presentations of work include Shocking Asia, Empty Gallery, Hong Kong, 2017; T
- published contributions
- Nick Srnicek
- litics of Free Time. His next research project wil
- published contributions
- Lizzie Stark
- Lizzie Stark is an author, journalist, and experience designer. She is the author of two books, Pandora’s DNA (2014), exploring so-called ‘breast cancer genes’ and her first book, Leaving Mundania (2012), which investigates the subculture of live action role play, or larp. Her journalism and essays have appeared in The Washington Post, the Daily Beast, The Today Show Website, io9, Fusion, the Philadelphia Inquirer and elsewhere. She holds an MS from the Columbia University Graduate School of Journalism. She has organized numerous conventions and experiences across the US. Her most recent work is as a programming coordinator for Living Games Austin, and as co-editor and contributor for the #Feminism anthology, which collects 34 nano-games written by feminists from eleven countries.
- published contributions
- Carolyn Steel
- Hungry City: How Food Shapes Our Lives, has gained bro
- published contributions
- Benjamin Steininger
- rlin. He works at the Cluster of Excellence “Unifying Syst
- published contributions
- Lucy Suchman
- ology of Science and Technology in the Department of Sociology at the University of Lancaster, UK. Her research interests within the field of feminist science and technology studies are focused on technological imaginaries and material practices
- published contributions
- Kaushik Sunder Rajan
- echnology studies, and postcolonial studies, holding a special interest in the global political economy of biomedicine, with a comparative focus on the Un
- published contributions
- Jenna Sutela
- Jenna Sutela’s installations, texts, and sound performances seek to identify and react to precarious social and material moments, often in relation to technology. Most recently, she has been exploring exceedingly complex biological and computational systems, ultimately unknowable and always becoming something new. Her work has been presented, among other places, at the Institute of Contemporary Arts, London; Haus der Kulturen der Welt, Berlin; and the Museum of Contemporary Art Tokyo and her writing has been published by Fiktion, Harvard Design Magazine, and Sternberg Press.
- published contributions
- Bronislaw Szerszynski
- Bronislaw Szerszynski is a Reader in Sociology at Lancaster University in the UK. Szerszynski’s work has developed across several themes, including the role of Western religious history in shaping contemporary understandings of technology and the environment—typified by his book Nature, Technology and the Sacred (Wiley-Blackwell, 2005).
- published contributions
- Elisa T. Bertuzzo
- Elisa T. Bertuzzo studied comparative literature, sociology, communication, and media studies and holds a PhD in urban studies. She was a curator and project leader with Habitat Forum Berlin, including for the project Paradigmising Karail Basti (2010–16). Bridging discourses from the fields of cultural and urban studies, her research focuses on the everyday life facets of urbanization and settlement in South Asia. On that topic, she published Fragmented Dhaka: Analysing Everyday Life with Henri Lefebvre’s Theory of Production of Space (2009) and runs her multimedia project Archives of Movement (since 2012), which deals with the everyday life of temporary labor migrants in Bangladesh and India.
- published contributions
- Gregory T. Cushman
- Gregory T. Cushman is Associate Professor of International Environmental History at the University of Kansas.
- published contributions
- Nasrin Tabatabai
- Nasrin Tabatabai is an artist who works both in Iran and the Netherlands. Since 2004, she has collaborated with Babak Afrassiabi on various joint projects and the publication of the bilingual magazine Pages (Farsi and English). Their work seeks to articulate the undecidable space between art and its historical conditions, including the recurring question of the place of the archive in defining the juncture between politics, history, and the practice of art. The artists’ work has been presented internationally in various solo and group exhibitions and they have been tutors at the Jan Van Eyck Academie, Maastricht (2008–13), and Erg, école supérieure des arts, Brussels (2015–).
- published contributions
- Ksenia Tatarchenko
- dies Institute, Geneva University, specializing in the history of Russian science and technology. She has held positions as a visiting Assistant Professor of History at NYU Shanghai and a post-doctoral fellow at the Harriman Institute, Columbia. Most broadly, she studies questions of knowledge circulation to situate Soviet developments in the global context. She is currently writing a book on science and innovation cultures in Siberia provisionally
- published contributions
- Katerina Teaiwa
- Dr. Katerina Teaiwa is Associate Professor at the Department of Gender, Media and Cultural Studies, School of Culture, History & Language and the president of the Australian Association for Pacific Studies. Her main area of research looks at the histories of phosphate mining in the central Pacific. Her work does not only span academic research, publications, and lectures, but also manifests itself in other formats within the arts and popular culture. Her work has inspired a permanent exhibition at the Museum of New Zealand Te Papa Tongarewa, which tells the story of Pacific phosphate mining through Banaban dance. In 2015, she published „Consuming Ocean Island: Stories of People and Phosphate from Banaba“, Indiana University Press. She is currently working with visual artist Yuki Kihara on a multimedia exhibition for Carriageworks in Sydney.
- published contributions
- Terre Thaemlitz
- record label. Her work combines a critical look at identity politics, including gender, sexuality, class, linguistics, ethnicity, and race, with an ongoing analysis of the socioeconomics of commercial media production. He h
- published contributions
- Jol Thomson
- published contributions
- Claire Tolan
- published contributions
- John Tresch
- published contributions
- Etienne Turpin
- Etienne Turpin is a philosopher, Founding Director of anexact office, and a research scientist at the Massachusetts Institute of Technology (MIT), Cambridge, where he coordinates the Humanitarian Infrastructures Group and co-directs the PetaBencana.id disaster mapping project for the Urban Risk Lab. He is the editor of Architecture in the Anthropocene: Encounters Among Design, Deep Tim
- published contributions
- Asonseh Ukah
- Asonzeh Ukah is a sociologist and historian of religion. He joined the University of Cape Town in 2013 and previously taught at the University of Bayreuth (2005–13), where he also earned a doctorate and habilitation in history of religions. His research interests include religious urbanism, the sociology of Pentecostalism, and religion and media. He is Director of the Research Institute on Christianity and Society in Africa (RICSA), University of Cape Town, and Affiliated Senior Fellow of Bayreuth International Graduate School of African Studies (BIGSAS), University of Bayreuth. He is the author of A New Paradigm of Pentecostal Power (2008) and Bourdieu in Africa (edited with Magnus Echtler, 2016).
- published contributions
- Underworlds
- published contributions
- Sebastian Vehlken
- Sebastian Vehlken is a media theorist and cultural historian at Leuphana University Lüneburg and Permanent Senior Fellow at the Institute for Advanced Study on Media Cultures of Computer Simulation (MECS). From 2013 to 2017, he worked as MECS Junior Director, and in 2015–16, he was a visiting professor at Humboldt-Universität Berlin, the University of Vienna, and Leuphana. His areas of interest include the theory and history of computer simulation and digital media, the media history of swarm intelligence, and the epistemology of think tanks. His current research project, Plutonium Worlds, explores the application of computer simulations in West German fast breeder reactor programs.
- published contributions
- Vladimir Vernadsky
- published contributions
- Ben Vida
- Korea, Australia ,and Europe at such institutions as the Guggenheim, New York; Centro Pecci, Prato, Italy; STUK Arts Center, Leuven
- published contributions
- Davor Vidas
- Davor Vidas is a research professor in international law and Director of the Law of the Sea Programme at the Fridtjof Nansen Institute, Lysaker, Norway. He is Chair of the Committee on International Law and Sea Level Rise and a member of the Anthropocene Working Group. Vidas has been involved in international law research for over thirty years, focusing since 2009 on implications of the Anthropocene for the development of international law. Among his books are The World Ocean in Globalisation (2011) and Law, Technology and Science for Oceans in Globalisation (2010). He is the editor-in-chief of the book series Anthropocene (Skolska knjiga, Zagreb), launched in 2017.
- published contributions
- Kalindi Vora
- transnational South Asian and diaspora studies, critical race studies, and cultural studies of gendered labor and globalization. In her
- published contributions
- Jennifer Walshe
- porary Arts, New York; DAAD Berliner Künstle
- published contributions
- Hannes Wiedemann
- Hannes Wiedemann is a Berlin-based photographer. He studied at the Ostkreuz School of Photography, Berlin. For his project Grinders (2015–16), he followed the American bodyhacking community, a small group of people across the United States working out of garages and basements to become real cyborgs. Recent exhibitions include NEW PHOTOGRAPHY II (2017) at Gallery ALAN, Istanbul, and HUMAN UPGRADE, with Susanna Hertrich (2016), at Schader-Stiftung Gallery, Hessisches Landesmuseum, Darmstadt. www.hanneswiedemann.com
- published contributions
- Elvia Wilk
- ze, Artfo
- published contributions
- Cary Wolfe
- Cary Wolfe is Bruce and Elizabeth Dunlevie Professor of English and Founding Director of 3CT: Center for Critical and Cultural Theory at Rice University, Houston. He is the author of What Is Posthumanism? (2010), a book that weaves together principal concerns of his work: animal studies, system theory, pragmatism, and post-structuralism. It is part of the series Posthumanities, for which he serves as Founding Editor at the University of Minnesota Press. His most recent publication is Before the Law: Humans and Other Animals in Biopolitical Frame (2013) and earlier books and edited collections include Animal Rites: American Culture, The Discourse of Species, and Posthumanist Theory (2003) and Zoontologies: The Question of the Animal (2003).
- published contributions
- Andrew Yang
- published contributions
- Jan Zalasiewicz
- Dr. Jan Zalasiewicz is Professor of Palaeobiology at the University of Leicester and Chair of the Anthropocene Working Group of the International Commission on Stratigraphy. A field geologist, paleontologist, and stratigrapher, he teaches and publishes on geology and earth history, in particular on fossil ecosystems and environments that span over half a billion years of geological time.
- published contributions
- Anna Zett
- published contributions
- Sander van der Leeuw
- ionships, and complex systems theory. He investigates the preconditions for and the practices and role of invention, sustainability, and innovation in societies. He has done
- published contributions
- Liv Østmo
- Liv Østmo is one of the founders and current Dean of the Sámi University of Applied Sciences, Kautokeino, Norway, where she researches and lectures on the subject of multicultural understanding. For the last eight years, Østmo has worked with traditional Sámi knowledge and she is currently working on putting the finishing touches on a methodology book about the documentation of this knowledge.
- published contributions
7. Mei-Jia & Ting-Ting & Chih-Fu & Sin-Ji